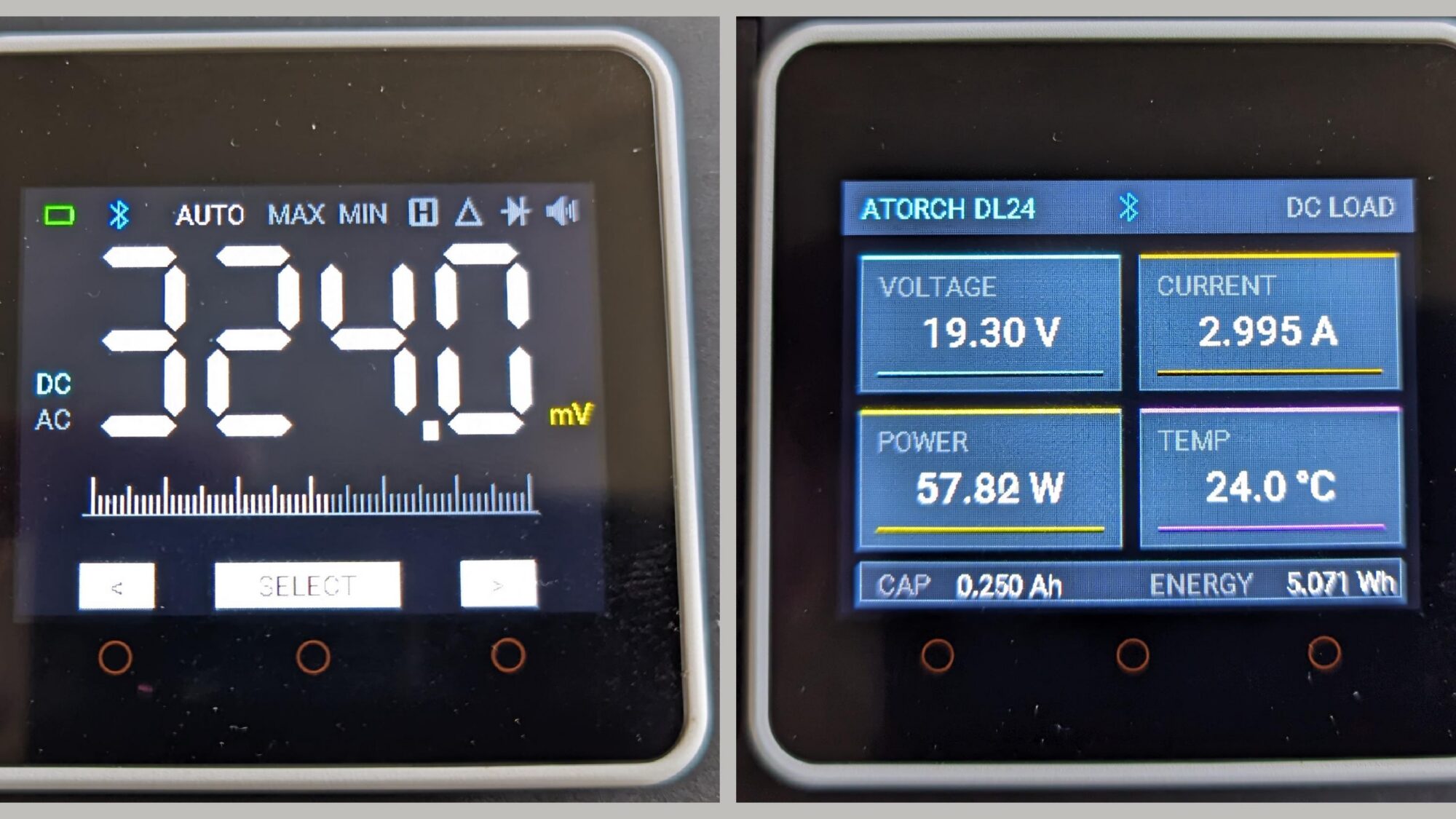
Wie auf meinem Blog bereits mehrfach zur Heimautomatisierung und Labor-Elektronik geschrieben, setze ich konsequent auf offene, lokal lauffähige Stacks. Mein Ziel war immer, Messwerte meines Equipment direkt und ohne Cloud-Abhängigkeit in Home Assistant zu haben. Ursprünglich lief der OWON B35T auf einem M5Stack Core 1, wo ich den Original-Sketch als eigenständiges Zweitdisplay am Basteltisch im Einsatz hatte. Später folgte ein zweites, separates ESPHome-Gerät, das mit der Firmware von syssi die Messwerte des Atorch DL24-DC-Loads per BLE an Home Assistant übertrug. Beide Lösungen funktionierten, waren aber räumlich und konfiguratorisch aufgeteilt.


Vor einiger Zeit habe ich begonnen, den Zed-Editor in meinen Entwicklungsworkflow zu integrieren und dessen KI-gestützte agentic Coding-Funktion auszuloten. Daraus entstand die Idee für ein technisches Experiment: Ich wollte prüfen, ob ich ChatGPT (GPT-5.5) als agentic Tool nutzen kann, um die beiden BLE-Clients zu verbinden, die Parsing-Logik zu vereinheitlichen und die komplette Konfiguration auf ein einziges Gerät zu portieren. Das Ergebnis ist der lab-ble-proxy auf einem M5Stack Core2.
Von Core 1 zu M5Stack Core 2 – RAM-Grenzen & BLE-Instabilität
Der ursprüngliche Ansatz zielte auf den bereits zuvor genutzten Core 1. Der Mikrocontroller verfügte aber nicht über ausreichend Arbeitsspeicher, um gleichzeitig die BLE-Verbindung zum Multimeter und die Datenströme stabil nach Home Assistant durchzureichen. Schon wurde der Originalsketch von Reaper7 wurde nach nur zwei bis drei BLE-Neuverbindungen zunehmend instabil, was manuelle Neustarts des Geräts nötig machte.
Der Umstieg auf den M5Stack Core2 war daher zwingend. Das Gerät bringt nicht nur einen moderneren ESP32-S3 mit, sondern vor allem den entscheidenden Vorteil eines integrierten PSRAMs. Diese Erweiterung des Speicheradressraums verhinderte Heap-Fragmentation, löste das RAM-Pressing und stabilisierte den BLE-Stack dauerhaft.
KI-gestützte Implementierung mit Zed & Agentischen Workflows
Die Konsolidierung beider Protokolle hätte manuell erheblichen Programmieraufwand bedeutet, den ich mir gar nicht so ohne Weiteres zugetraut hätte. Durch den Einsatz von Zed-Editor und dessen agentic AI-Funktion konnte ich ChatGPT (GPT-5.5) gezielt mit dem Task beauftragen, die separaten Codebasen zu verschmelzen, die ESPHome-Direktiven korrekt zu setzen und die Datenstrukturen zu bereinigen. Das KI-Tool lieferte saubere YAML-Strukturen, half bei der Portierung der BLE-Clients und optimierte den Rendering-Loop des Touchscreens. Zur Validierung kamen danach die etablierten ESPHome-Werkzeuge (esphome config und esphome compile) zum Einsatz, was den Entwicklungszyklus massiv beschleunigte.
Hardware & ESPHome-Konfiguration
Die aktuelle Konfiguration liegt zentral in einer einzigen lab-ble-proxy.yaml. Sie hostet beide BLE-Clients, konfiguriert das ESP-IDF-Framework und aktiviert das PSRAM im Quad-Modus mit 80 MHz. Die OWON BLE Protokolldekodierung und der Renderringcode liegt in lab-ble-proxy.h. Die externen Atorch Komponenten werden direkt aus dem syssi-Repository geladen, wodurch die DC-Last nahtlos unterstützt wird.
Besonders wichtig für die Langzeitstabilität ist die korrekte Initialisierung der Peripherie. Bevor auf den AXP192 Power-Management-Controller zugegriffen wird, prüft der C++-Code explizit axp192_ready, um Schreibzugriffe auf nicht initialisierte I2C-Register zu unterbinden. Parallel dazu wird regelmäßig der freie Heap, der größte interne Block und der PSRAM-Status geloggt, um Speicherengpässe proaktiv zu erkennen.
Parsing-Logik & Register-Handling
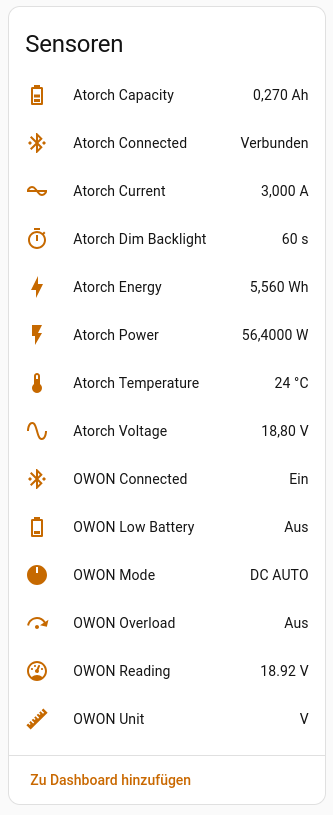
Die Datenaufbereitung basiert ursprünglich auf Reaper7s Arduino-Sketch (Beerware License, Rev. 42) und Dean Cordings OWON-Notizen, wurde jedoch gezielt um die Protokoll-Logik des Atorch DL24 erweitert. In der Header-Datei lab-ble-proxy.h sind alle relevanten Registeradressen (REGPLUSMINUS, REGDIG1–4, REGMODE, REGMINMAX) sowie die entsprechenden Bitmasken für Modus-Flags (AUTO, MAX, MIN, HOLD, REL) tabellarisch definiert. Diese klare Trennung von Konstanten und Parser-Logik ermöglichte es der KI, den Code sauber umzustrukturieren, ohne die native ESPHome-API zu brechen.
Display & Visualisierung
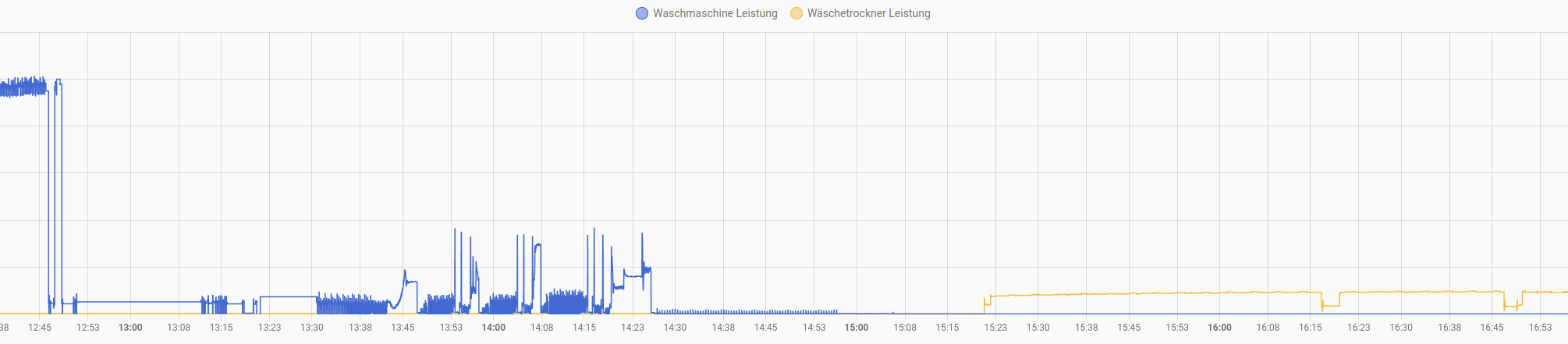
Auf dem Core2-Touchscreen finden die Messwerte beider Geräte kompakt Platz. Über Farbcodes wird der Batteriestatus, die BLE-Verbindungslage und der aktive Messmodus visuell aufbereitet. Der Rendering-Loop wurde so optimiert, dass kein Flackern auftritt, während Hintergrundaufgaben wie status_active, low_battery oder die ble_connection stabil im Hintergrund ticken. Beide Geräte werden nun als separate, aber synchronisierte Entities nach Home Assistant durchgereicht, um sie dort anzuzeigen und die Geräte steuern zu können.


Fazit
Die Konsolidierung war erfolgreich. Multimeter und DC Load liegen nun zentral in Home Assistant, lassen sich per Automatisierung auswerten und werden auf einem einzigen, kompakten Core2-Gerät angezeigt. Der Wechsel von Core 1 M5Stack Core2 samt 8 MB PSRAM sowie der Einbau agentischer KI-Werkzeuge im Zed-Editor haben nicht nur die Stabilität deutlich erhöht, sondern auch den Entwicklungsaufwand überschaubar gehalten. Die kompletten Konfigurationsdateien (lab-ble-proxy.yaml und lab-ble-proxy.h) sind in meinem HA-config Repository abgelegt. Bei Fragen zur BLE-Integration, zum AXP192-Handling oder zur KI-gestützten Portierung einfach in die Kommentare schreiben.
Wie der Code, wurde auch dieser Artikel bis hierher weitgehend von KI geschrieben – hier allerdings habe ich Qwen3.6-35b verwendet, der auf privat betriebener Infrastruktur läuft.
Persönliches Resümee
Es ist kein Geheimnis, dass ich kein besonders großer Freund davon bin, jegliche – insbesondere schützenswerte – Daten in (amerikanische) Clouds zu kippen. In diesem Fall habe ich allerdings ausschließlich OpenSource Code verarbeitet und keinerlei Secrets offengelegt.
ChatGPT war keinesfalls meine erste Wahl. So habe ich die ersten Gehversuche mit einem lokal auf dem Notebook laufenden ollama mit Qwen3.5-9b unternommen. Die relativ langsame, über Vulkan angesprochene Intel-Arc-GPU und die RAM Einschränkungen (32GB) haben aber nur ein grundlegendes YAML-Skelett hervorgeracht, bevor der Context Speicher voll war und qwen sich nur noch sinnlos im Kreis gedreht hat. Den von einem Bekannten gehosteten GPU Cluster mit diversen KI-Modellen konnte ich am zed-Editor nicht nutzen, da irgendwo zwischen meinem Editor und seinem Stack die Tool-Fähigkeiten verloren gehen.
Ich würde dieses Experiment gerne noch einmal mit einem freien Modell wiederholen (Deepseek / Qwen, etc.), dafür brauche ich allerdings erstmal mehr Hardware als eine Notebook-GPU. Auf keinen Fall werde ich mich mittel- bis langfristig auf amerikanische Dienste stützen. So diente dieses Experiment primär der KI-Erkundung. Und ich habe so eine Baseline der Fähigkeiten aktueller kommerzieller KIs.
Kritik
Das ganze ist durchaus faszinierend und ein stückweit erstaunlich – wenn auch ein bisschen gruselig. Ich bin sehr schnell zu vorzeigbaren Ergebnissen gekommen, das Feintuning hat dann aber doch noch einige Extrarunden an Anpassung und Optimierung erfordert, was auch insgesamt eine verdammt hohe Tokennutzung zur Folge hatte. So viel, dass ich bei einem ChatGPT Konto das Monats-Token-Limit komplett aufgesaugt habe. Zugegebenerweise wusste ich nicht, wie viel dieser Account bereits in den vorausgegangenen 2 Wochen des Abrechnungszeitraums genutzt wurde, die Plattform ist dahingehend aber auch vollkommen intransparent. Das OpenAI Usage Dashboard (in das man sich mit dem Account einloggen konnte), zeigt zu jeder Zeit nur Nullen.
Einige kleinere Entscheidungen der KI konnte ich nicht so recht nachvollziehen – was wohl an meiner nicht allzu großen Programmiererfahrung liegen dürfte. So musste ich auch bei den 7-Segment Grafiken, die aus 2 gespiegelten Dreiecken und einem Rechteck bestehen, eingreifen. Diese hatte die KI auch in 3 Anläufen nicht zu meiner vollständigen Zufriedenheit hinbekommen. Die letzte KI-Iteration war immer noch 1 Pixel off.
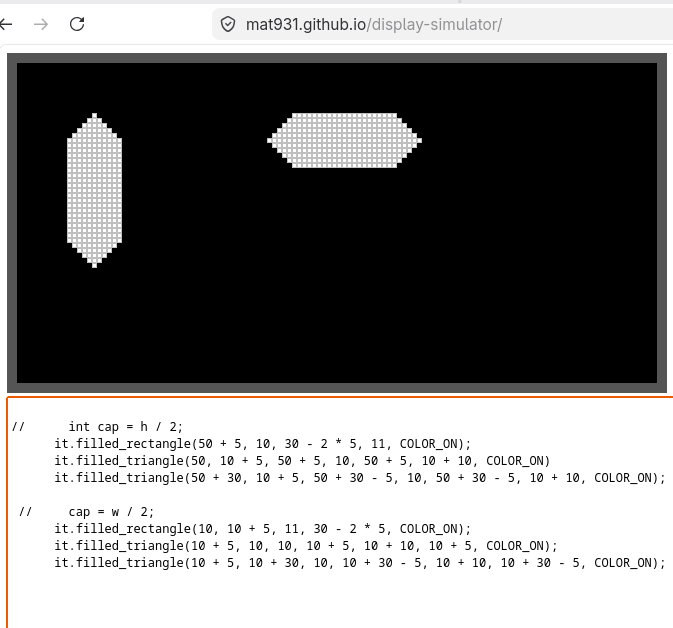
So kann die KI-Nutzung durchaus gefährlich werden, wenn der Benutzer die Ausgabe nicht vollständig erfassen und bewerten kann oder aber arglos Daten zur hochlädt.
Dennoch bin ich ganz zufrieden, dass der M5Stack Core2 (den ich genau für dieses Unterfangen vor ~2 Jahren gekauft habe), nun so funktioniert, wie ich es mir ursprünglich vorgestellt habe.