
Beflügelt durch den geplanten Tschernobyl-Trip, der von COVID-19 vereitelt wurde, hat eine Freundin die Metro Trilogie von Dimitry Glukhovsky verschlungen. Die Bücher habe ich ebenfalls vor einiger Zeit gelesen. Auf der Suche nach mehr relatiertem Lesestoff, sind wir auf die „S.T.A.L.K.E.R.“-Reihe gestoßen, die seiterzeit im Panini-Verlag erschienen ist. Leider werden die Bücher nicht mehr (neu) verkauft – und schon gar nicht in digitaler Form als eBook.
Was mich auf die Idee brachte, einfach mal den ersten Band auf dem Gebrauchtbuchmarkt zu klicken, um zu evaluieren, ob und wie gut es möglich wäre, den Inhalt mit Open-Source-Software zu digitalisieren und als eBook im epub Format zu verpacken.
Ziel sollte es sein, dass die Freundin das Buch im Papierformat und ich das eBook auf dem Kindle lesen kann. Warum das natürlich nicht funktionieren konnte, darauf komme ich im Fazit auch noch zu sprechen.
Meine Open-Source eBook Toolchain
Wie man sich unschwer ausmalen kann, ist das Unterfangen eine ziemlich repetitive Abfolge, von immer gleichen Arbeitsschritten. Daher sollten weite Teile geskriptet werden können und weitgehend ohne menschliche Interaktion vonstatten gehen.
Schritt 1: Scannen der Buchseiten
Der erste Schritt muss natürlich erstmal das Scannen der Buch(doppel)seiten sein. Eine gute Idee dabei war, die Seiten erst einmal als Bild einzuscannen und nicht direkt von einer OCR-Software verwursten zu lassen. Das lässt die Möglichkeit, die Bilder vorab für die Erkennung optimieren zu können. Da gehört sowohl die Erhöhung des Bildkontrastes dazu als auch das Entfernen noch Scan-Artefakten wie der Knick in der Mitte der Buch-Doppelseiten. Deswegen scanne ich in Graustufen und speichere die Bilder verlustfrei als png.
Um nicht jedes Bild nachträglich beschneiden zu müssen und den Scanvorgang zu beschleunigen, beschneide ich direkt mit Parametern für scanimage (aus der SANE software suite). Eine höhere Auflösung scheint die Erkennungsergebnisse nicht signifikant zu verbessern, dauert bei meinem ~20 Jahre alten Scanner aber deutlich länger (~ +50%).
scanimage -d plustek:libusb:002:036 -p --resolution 300 --format=png --mode=Gray -l 0 -t 0 -x 180 -y 240 -o 001.pngCode-Sprache: Bash (bash)Bewährt hat es sich, die dünnere Seite des Buchs mit einem Gegenstand (auch hierbei ist der Kindle sehr praktisch :D) auszugleichen und den Scannerdeckel zu beschweren. Unscharfe Zeichen in der Buchmitte sind dabei ein absolutes No-Go für die OCR-Software – genauso wie ein Verrutschen der Scanvorlage während des Scans. Daher kontrolliere ich jedes Bild manuell (während der Scankopf zurückfährt). Je besser der Scan, desto weniger Fehler macht ‚tesseract‘, was später deutlich Arbeit erspart.
Schritt 2: Bilddateien für die Erkennung vorbereiten
Nun, da alle Buch-Doppelseiten als .png vorliegen, wende ich Software darauf an, um eine fehlerfreie(re) Erkennung zu gewährleisten. Zuerst drehe ich die Buchseiten, was ich auf die Original-Scans anwende, für alle weiteren Schritte erstelle ich Zwischendateien. ‚mogrify‘ ist das Batch-Pendant zu ‚convert‘ aus der ImageMagick Suite. Positive Werte drehen im Uhrzeigersinn, negative in die entgegengesetzte Richtung.
mogrify -rotate -90 scans/*.pngCode-Sprache: Bash (bash)
Nun erhöhe ich den Kontrast und schärfe das Bild ein wenig:
mogrify -format pgm -path processed/ -level 40%,70% -sharpen 0x1 scans/*.pngCode-Sprache: Bash (bash)Man könnte hier auch noch die Option -normalize verwenden, die den Kontrastbereich der Ausgabe auf sehr harte Werte vergrößert. Dabei bleibt fast ein schwarz/weiß Bild übrig. Allerdings führt das im nächsten Schritt zu Problemen mit ‚unpaper‘, sodass ggf. ganze Zeilen oder gar Teilabsätze entfernt werden.

Als letzten Schritt des Preprocessings jage ich noch ‚unpaper‘ über die Seiten. Das Tool entfernt alle Bildbestandteile, die es als nicht zum Text zugehörig erachtet. Das klappt auch weitgehend ganz gut. Ränder, der Knick und etwaige Verunreinigungen verschwinden so nahezu komplett. Wegen unpaper habe ich die Bilder auch im letzten Schritt in das pgm – Format umgewandelt, weil dieses nur pbm/pgm verarbeiten kann. Beides sind unkomprimierte Bitmap-basierte Formate – das eine für schwarzweiß Bilder, das andere für Graustufen.
unpaper -l double processed/%03d.pgm unpapered/%03d.pgmCode-Sprache: Bash (bash)
Da auch die Ausgabedateien wieder im pgm Format sind, wandele ich alles wieder verlustfrei nach png zurück, um Speicher zu sparen.
mogrify -format png -path final/ unpapered/*.pgmCode-Sprache: Bash (bash)Die Ordner processed und unpapered könnte man nun wieder löschen. Die Originale sind in scans noch vorhanden und die Daten, auf die ich gleich ‚tesseract‘ loslasse, liegen nun als png im Ordner final.
Schritt 3: OCR-Erkennung mit tesseract
Die so vorbereiteten Daten kann man nun auf einen Schlag ‚tesseract‘ vor die Füße werfen.
for f in *.png;do tesseract --psm 1 -l deu "$f" "$(basename "$f" .png)";doneCode-Sprache: Bash (bash)Dabei kommt zu jedem Bild passend eine txt-Datei heraus, die zwar keine Formatierung (wie fett oder kursiv) mehr enthält, aber ansonsten der Bildvorlage entspricht – inkl. Worttrennungen und Zeilenenden. Das alles händisch zu bearbeiten ist ganz schön nervtötend und zeitaufwendig. Nervtötend ist auch der Umgang mit RegEx-Ausdrücken, aber dafür läuft das maschinell automatisch, wenn man sich die einmal zusammengebaut hat.
Schritt 4: OCR-Fehler bereinigen und Zeilenumbrüche entfernen
Beim Korrigieren des ersten Buches ist uns aufgefallen, dass tesseract eine Vorliebe für eine Handvoll Erkennungsfehler hat. So wird ein „i“ mitunter als ein „i ohne Punkt“ (ı) interpretiert, orthographische Abführungszeichen (“) häufiger als „normale“. Und aus einem „ß“ wird mitunter ein „B“. Schwierig sind auch Gedankenstriche (—).
grep -RiIl ı final/*.md | xargs sed -i 's/ı/i/g'
grep -RiIl " - " final/*.md | xargs sed -i 's/ - / — /g'
grep -RiIl \" final/*.md | xargs sed -i 's/\"/“/g'
egrep '\SB\S' work/*.mdCode-Sprache: Bash (bash)Der letzte Befehl sucht tatsächlich nur „B“ innerhalb von Worten. Hier muss die Korrektur händisch erfolgen. Aber der Befehl gibt die Datei mit dem Treffer aus. Das konnte ich leider nicht vollständig automatisieren, weil ich RegExen nicht gut genug beherrsche, um die false-Positives auszufiltern.
for f in *.md;do perl -0 -pe 's/-\n//g;' -pe 's/(?<!\n)\n(?!\n)/ /gm;' -pe 's/\n\n+/\n\n/gm;' "$f" > ../work/"$f";doneCode-Sprache: Bash (bash)Dieses unleserliche Monstrum entfernt alle Worttrennungen und Zeilenumbrüche, erhält aber Absätze (mit 2 newlines).
Schritt 5: Nachbearbeitung im markdown-Format
Wenn man sich anschaut, was die gängigen eBook-Formate (epub und azw3 / mobi) eigentlich sind, stellt man schnell fest, dass alle im Prinzip zip-Files sind, die HTML, CSS, Bilder und ggf. TrueType/OpenType fonts enthalten. Daher macht es Sinn, die Formatierung mit HTML-Tags wiederherzustellen. Einfacher und bequemer zu tippen ist es aber als Markdown. Aus diesem lässt sich schnell und einfach am Ende wieder HTML generieren. Also erstmal alle txt-Dateien in md umbenennen, damit gängie Texteditoren nicht verwirrt sind.
rename .txt .md *.txtCode-Sprache: Bash (bash)Nun kann man die erkannten Text seitenweise bearbeiten (und mit der OCR- oder Scanvorlage vergleichen). Hierbei gilt es, die restlichen Erkennungsfehler zu finden und zu eliminieren und die Formatierung wiederherzustellen. Hierbei war dieses Markdown-Cheatsheet sehr nützlich.
Um später alles einfach zu einem Dokument zusammen konkatenieren zu können, sollte man einheitliche Konventionen benutzen. Z. B. das getrennte Wort von der folgenden Seite auf die vorherige rüberziehen und lediglich mit einem Leerzeichen abzuschließen. Auch den Absatz-newline belasse ich auf der vorherigen Seite, um die darauffolgende direkt mit einem druckbaren Zeichen beginnen zu können. Am Ende wird alles zusammen nacheinander in eine Datei geschrieben, mit der ab jetzt ausschließlich weiter gearbeitet wird. Das markdown-file ist nun das Hauptdokument, aus dem alle anderen Formate erzeugt werden können.
cat *.md > Titel.mdCode-Sprache: Bash (bash)Machen wir uns nichts vor. Egal, wie gründlich man gearbeitet hat, es werden noch Fehler in ‚Titel.md‘ vorhanden sein. Diesen sollte man nun noch einmal in Gänze korrekturlesen – wir haben dies sogar 2x gemacht.
Nun macht es Sinn, korrekte, hierarchische Überschriften zu verwenden. Sind diese im fertigen HTML schon enthalten, ist die Erstellung des Inhaltsverzeichnisses später eine Sache von 2 Mausklicks. Ich habe z. B. h1 bis h4 verwendet, wobei ich für das Inhaltsverzeichnis nur h1-h3 berücksichtige. h4 verwende ich so nur für die Wahl des Fonts für Ortsangaben im eBook.
Mit dem schlanken Kommandozeilentool ‚multimarkdown‘ kann man nun eine HTML-Datei erstellen, die alle markdown-Formatierungen enthält, aber kein unnötiges CSS mitschleift.
multimarkdown -o 1-Titel.html -l de -t html 1-Titel.mdCode-Sprache: Bash (bash)Schritt 6: EPUB erstellen
Warum ich mich für epub entschieden habe, obwohl mein Kindle das Format gar nicht lesen kann? Weil es ein offener Standard ist, aus dem sich die Propietären mit der Software Calibre leicht konvertieren lassen. Mit Sigil gibt es auch eine brauchbare Open-Source Software, die epub erstellen kann. Diese beiden Tools sind tatsächlich grafische Programme – im Gegensatz zu allen anderen zuvor verwendeten.
Zuerst erstelle ich ein neues EPUB Projekt und füge die Metadaten mittels Metadaten-Editor hinzu. Anschließend importiere ich Cover und Logos, die ich aus den processed Bildern herausgeschnitten habe im jpg, bzw. png Format. Optional kann man natürlich noch hübsche Schriftarten hinzufügen. Ich hatte mich hier für 2 freie entschieden. Das muss man dann natürlich beim Schreiben vom CSS berücksichtigen, damit sie auch verwendet werden.
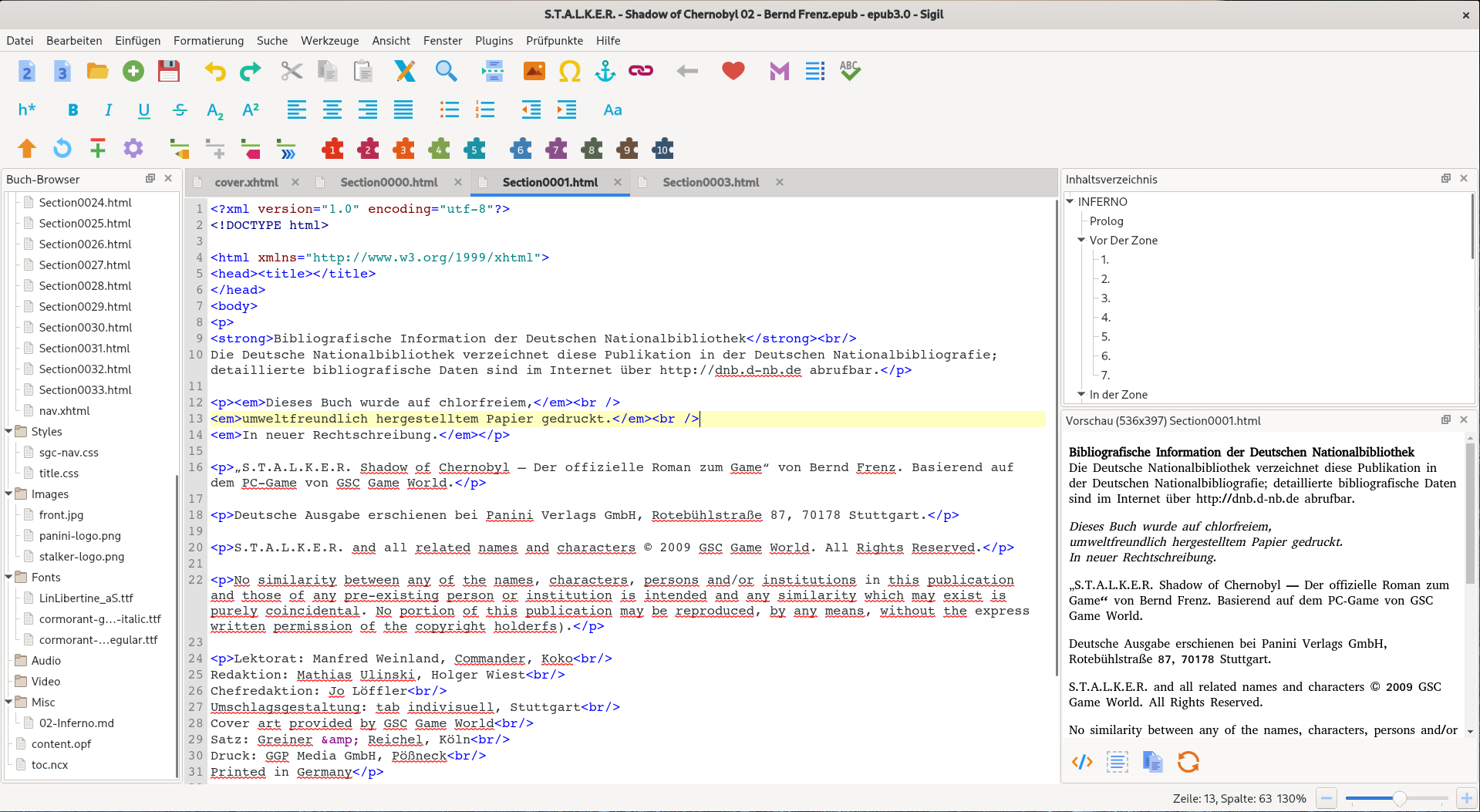
Nun füge ich das monolithische HTML-Dokument hinzu. Das könnte so schon reichen, für ein funktionierendes eBook. Mein Kindle frisst das so auch. Ich las aber, dass vor allem ältere Geräte durchaus ein Problem damit haben könnten, knapp 500KB HTML am Stück zu laden und zu parsen. Empfohlen wird daher die Auftrennung in einzelne Kapitel. Dies geht schnell und einfach mit dem Knopf „Teilung am Cursor“, der nicht mit einer Tastenkombination versehen ist. :-$ Immerhin kümmert er sich Übernahme von verknüpften Stylesheets und erzeugt wieder ein valides Dokument.
Das Inhaltsverzeichnis kann anschließend vollautomatisch mit Werkzeuge -> Inhaltsverzeichnis -> Inhaltsverzeichnis erstellen (Strg+T) erzeugt werden. Werkzeuge -> Cover hinzufügen setzt ein zuvor hochgeladenes Bild als Cover-Bild.
Ich schrieb zuvor, dass ich Newlines zwischen Absätzen erhalten habe. Das habe ich getan, weil bei der Umwandlung von Markdown zu HTML nun jeder Absatz ein eigenständiger Paragraph ist, den man nun schick stylen kann. Tatsächlich ist das CSS-Stylesheet aber wirklich sehr übersichtlich. Das reicht aber schon, um die digitale Erscheinungsform der Buchvorlage anzunähern.
/* cormorant-garamond-regular - latin */
@font-face {
font-family: 'Cormorant Garamond';
font-style: normal;
font-weight: 400;
src: local('Cormorant Garamond Regular'), local('CormorantGaramond-Regular'),
url('../Fonts/cormorant-garamond-v7-latin-ext-regular.ttf') format('ttf'),
}
/* cormorant-garamond-italic - latin */
@font-face {
font-family: 'Cormorant Garamond';
font-style: normal;
font-weight: 400;
src: local('Cormorant Garamond Regular'), local('CormorantGaramond-Italic'),
url('../Fonts/cormorant-garamond-v7-latin-ext-italic.ttf') format('ttf'),
}
/* cormorant-garamond-bold - latin */
@font-face {
font-family: 'Cormorant Garamond';
font-style: normal;
font-weight: 400;
src: local('Cormorant Garamond Regular'), local('CormorantGaramond-Bold'),
url('../Fonts/cormorant-garamond-v7-latin-ext-bold.ttf') format('ttf'),
}
/* linux-libertine-capitals - latin */
@font-face {
font-family: 'Linux Libertine';
font-style: normal;
font-weight: 400;
src: local('Linux Libertine Capitals'), local('LinuxLibertine-Capitals'),
url('../Fonts/LinLibertine_aS.ttf') format('ttf'),
}
body {
font-family: "Cormorant Garamond";
}
h2, h2, h4 {
font-family: "Linux Libertine Capitals";
}
p {
text-indent: 1em;
margin: 0;
}Code-Sprache: CSS (css)Fazit
Wie schon am Anfang gespoilert, ist das Ziel eigentlich vollkommen verfehlt, denn keiner von uns konnte das Buch in der präferierten Form lesen. Im Endeffekt haben wir es beide am Notebook im Markdown – während der Bearbeitung – gelesen, sodass die eBook-Formate nun lediglich in die digitale Privatbibliothek wandern. Auch Veröffentlichen kann ich sie nicht, weil Text und Bilder natürlich geistiges Eigentum Anderer sind.
Fragt mich also bitte nicht, ob ich die epubs als unlizensierte Kopie herausgeben kann. Das kann und werde ich nicht.
So gesehen war dies eine sehr sinnlose, aber spaßige Arbeit, durch die ich einiges Neues gelernt habe. Dementsprechend steht es in den Sternen, ob wir diese Nummer tatsächlich für alle 11 (ins Deutsche übersetzte), bzw. 13 Bücher durchziehen werden, denn wir reden hier von einem Zeit- und Arbeitsinvest von annähernd 2-4 Menschtagen pro Buch.





Hallo
Wir haben viele Bücher aus einem Raucherhaushalt digitalisiert.
Wenn ein Reader vorhanden, ist der die Comicbook-Formate cbz lesen kann, dann gibt es eine wesentlich einfachere Methode:
Einscannen, (Seitenzahl = Dateiname) mit Scantailor zuschneiden, mit Xnview im Batch aufhübschen und dann in einen Zip-Datei speichern. DIese zip dann in cbz umbenennen und fertig.
Die Datei ist zwar größer als eine PDF oder epub, aber Speicherplatz ist günstig.
Bewährt hat sich bei uns ein iPAD oder ein Pocketbook Inkpad in 8″…